
Introduction
I recently had to migrate a heavily trafficked and highly sensible service from EC2 into Kubernetes. The main challenge was that there could be no down time, and no data loss, a typical request — yet this service presented somewhat of a challenge due to its intricacies of how it was built and how it behaved, differentiating it from a typical application. So I thought it would be a good topic of discussion on how to actually perform this through a system design perspective. The procedure I’m going to go through here is applicable to SQS, RabbitMQ, Kafka or whatever Broker you are using so it’s platform independent!. This post is infrastructure components related, no network dimensions are analyzed here.
Architecture
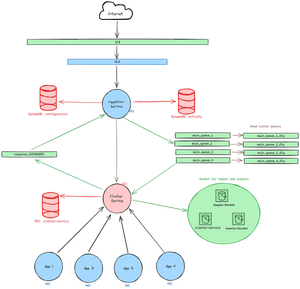
First let’s look at the architecture of this component to see the initial state.
For the sake of example, we will be migrating a service called cluster-service (because it’s a service… in a cluster… yes, naming things is my passion) from EC2 (red) to a Kubernetes environment (blue) which already has some apps already in K8s, building on this example we will add a calling server upstream of cluster-service called ingestion-service and 1-4 random app pods downstream of cluster-service so it looks like a typical production environment. The only method of communication between cluster-service and ingestion-service is through queues: ingestion service publishes to 4 different queues, each one of them has a dead letter queue (DLQ), cluster-service is subscribed to all of these queues and in order to respond to ingestion-service it publishes to another queue called response_${RANDOM} and ingestion-service is subscribed to this queue.
Downstream apps can call cluster-service directly and not through queues, also both services have their own databases and are hooked up to S3 buckets. All in all, a very broker-heavy architecture, now the question is, how do we migrate cluster-service from EC2 into Kubernetes with no downtime?
Restrictions
Now let’s add some common restrictions to our problem.
- Let’s say that when
cluster-servicereceives a message from the upstream queues, it begins to process it. While the message is in thecluster-servicepod , it becomes a non transactional process, so a sudden restart of the pod/instance would throw an error of execution, returning an error to the user but triggering a retry on the upstream queue fromtrigger-ingestionto attempt the execution again. Not exactly ideal but it’s not the end of the world, nonetheless, it’s an outcome we wish to avoid. The restriction here is that any execution within any given instance could run for as long as 15 minutes. This means that if we do a swap from EC2 to Kubernetes we would have to wait 15[min] at most. - The queues can’t be shared, so this means that the queues consumed by kubernetes cannot be the same as the queues being consumed by EC2. This is the principal of isolation when doing a migration. There are cases when you can’t migrate an infrastructure component during a migration and have to share it between the instances. In this case, we are doing a full migration of all components.
- Lastly, we need to analyze queue drainage, when the queues are being consumed by
cluster servicewe need to know which messages come from EC2 and which ones are being processed by Kubernetes pods, the restrictions placed on us as cloud engineers from the application team is that the request can only be processed by one instance be it either EC2 instance or Kubernetes pod during the blue green migration. If the queues fail for whatever reason, it needs to fallback to the original queue for processing on the EC2 instance.
Dead Letter Queues
Now, before we continue, I have to explain what’s the deal with Dead Letter Queues in case you don’t know, you can read more about them in Wikipedia but as the name suggest, it’s a queue, no different from the ones you know, whose only purpose is to store “dead” messages from other queues it is attached to. For example, imagine that you have a queue and it fails to reach a subscriber, or it reaches it’s TTL limit, should the message be deleted and lost forever? Depends on your application! But, what if you need to ALWAYS process the messages, no matter what, but don’t want your main queue to build up messages and adding latency to your active workloads? Just dump them on a dead letter queue and process them later through another process!. Anyway, all they are is a backup to failures on the “main” queue, but we can use this component for our migration needs.
The Plan: Handling Failures on New Queues
Now, into the system design bit. We are going to use the DLQs to act as proxies between the queues in Kubernetes and EC2. We do this because as we are migrating and shifting traffic we never know if there will be failures on the environment you are migrating to, so the fear comes from the fact that you swap 10% of the traffic to your shiny new environment and you get cascading failures until you frantically run through commands and UIs to swap traffic back, all those messages lost! Which in turn, leads to angry users. So what we want is to have a way of capturing failed messages in the queue and store them in a dead letter queue, so even if you fail in your initial swap ( it’s not always infrastructure related, app developers make mistakes too! ) you can still recover and process those messages. So let’s go through the proposed blue-green architecture.
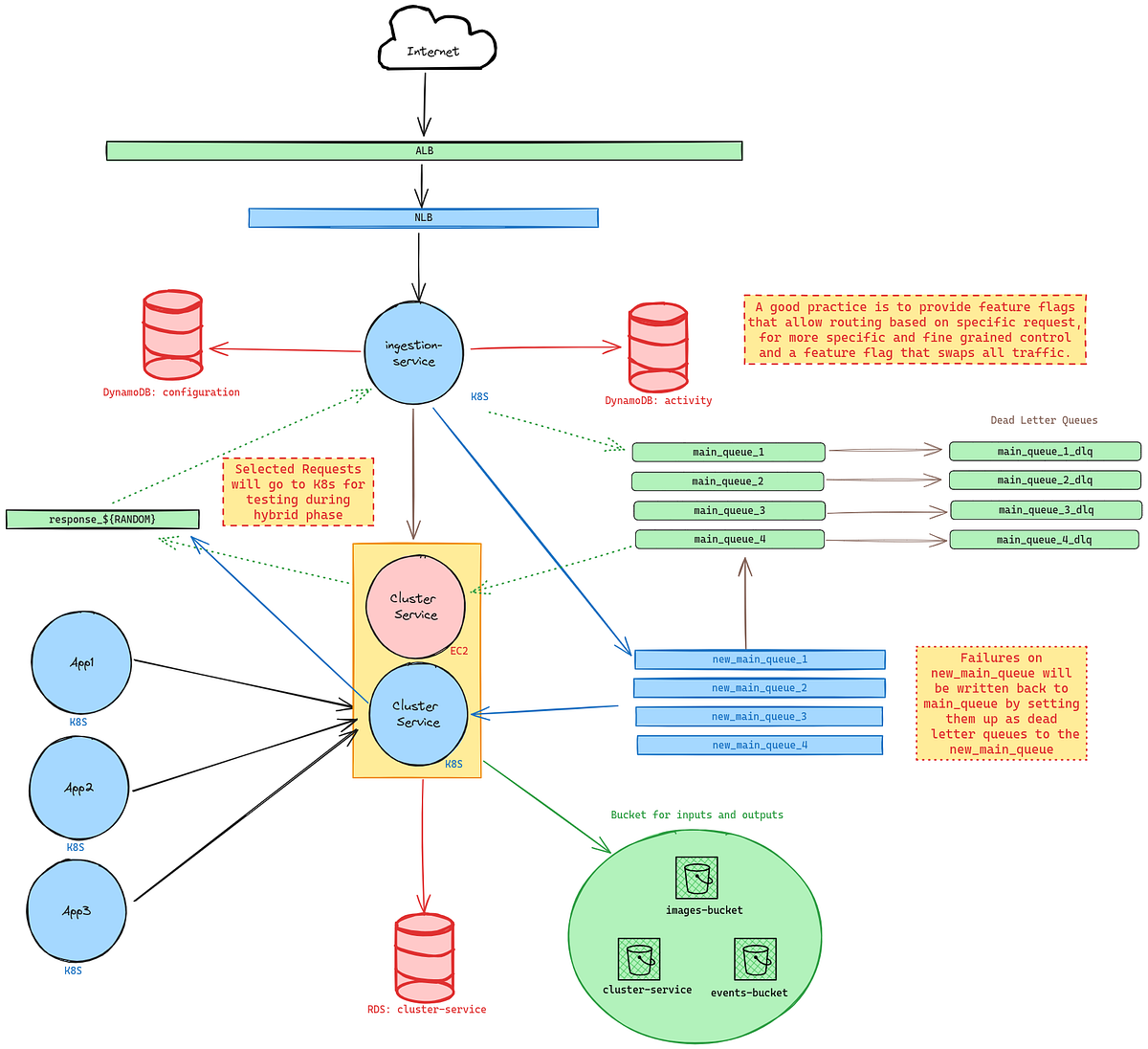
To accommodate our restrictions, we duplicate whatever queue resources we had before and make sure they are used exclusively by the K8s pods, while the original queues stick with EC2, this way we know what flavor of cluster-service is doing the work for which messages.
As you can see from the architecture diagram, ingestion-service will push only selected requests (this has to be handled by your application, I use a global DynamoDB config but you can use whatever you like), to K8s via the new_main_queues, when processing the message in the pods, should there be a failure while processing the message, it will report back to the new_main_queue , that it failed to process, and then discard that message to its DLQ, but the DLQ for the new_main_queue is actually the original main_queue that is pushing messages back to EC2 instances!
The Plan: Handling Non Transactional Requests
When migrating applications that are processing messages from queues, you don’t want to shut them down instantaneously. What needs to happen is to block all incoming request and find out how much time your application needs in order to process the current message and not ingest anymore. This has to be handled by both EC2 and K8s deployments.
On the EC2 side, it’s easy enough to accomplish this by removing the EC2 instance from a target group. By doing this, no more traffic will flow into the app and all that is left to do, is to wait for the 15[min] (could be different for your app) to process whatever execution is happening on the instance.
On the K8s side of things, this is solved by adding pod PreStop hooks and putting the container to sleep for 900[sec] (15[min]). This way, the container (as soon as it is killed by anything) will hang around for 15 minutes in termination state, there are two benefits to this.
apiVersion: v1
kind: Pod
metadata:
name: cluster-service
spec:
containers:
- name: cluster-service
image: cluster-service
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","sleep 900"]- When killed, the pod in terminating state has its
Endpointobjects removed and thus, no traffic will be routed to it by theServiceresources, thereby killing all traffic to it to prevent new queue messages from reaching it. - Since it is in
Terminatingstate, it will continue executing whatever request it was processing until the 15 minutes are up, respecting, in turn, our SLA for executions.
Final State
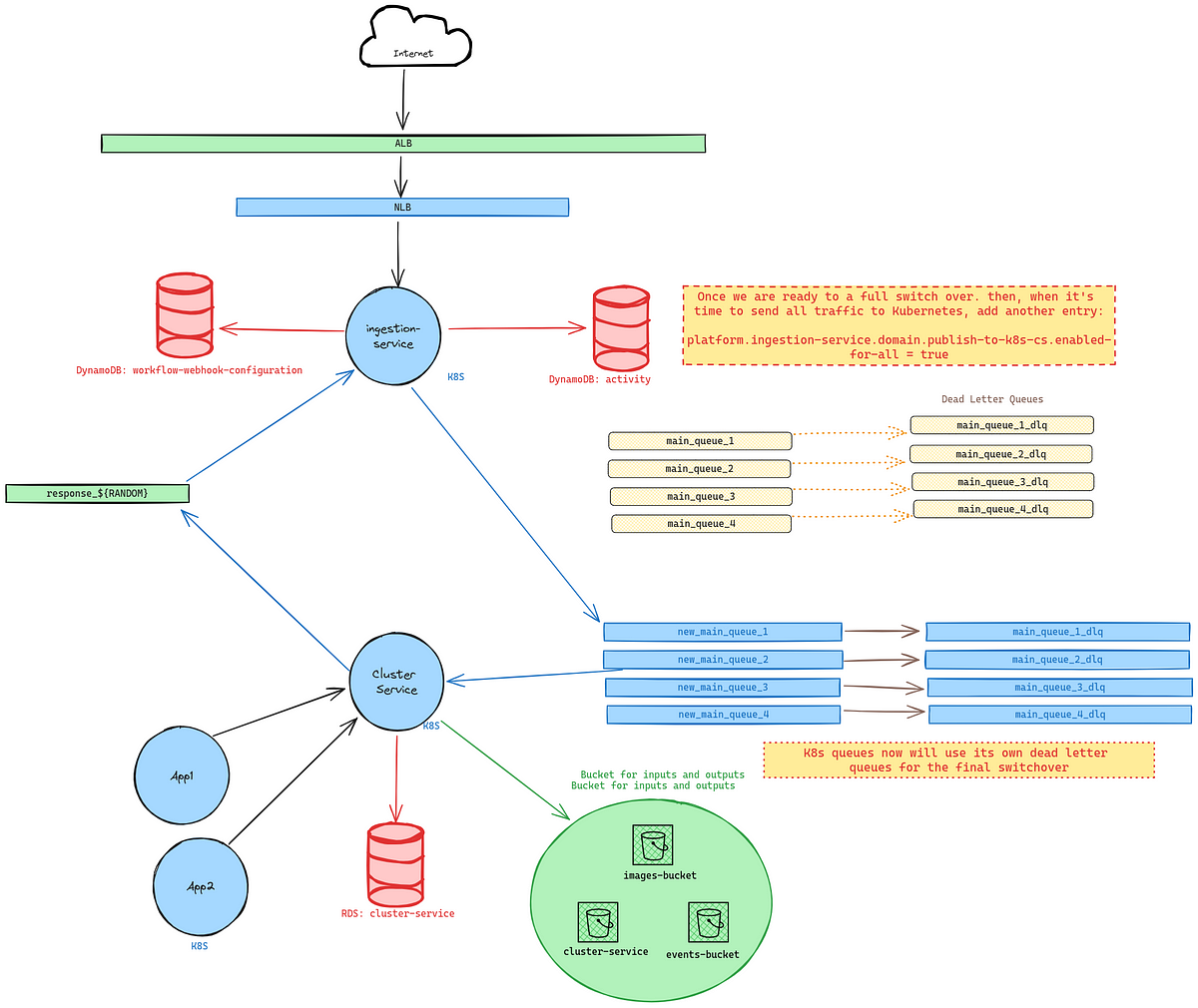
The final state of the application should be all EC2 instances shut down and the only instance of cluster-service should be a pod in the EKS cluster, the new_main_queues should now have their own DLQs similar to the initial state as shown on the following image.
Final thoughts
When swapping over and cleaning up, there may still be lingering messages that need to be processed on the old queues that for whatever reason were unable to be processed. Make sure that they are safe to delete before completely destroying the queue resources.
With this approach, you won’t have to deal with duplicate messages as the flow of messages is still uni-directional. If during the hybrid phase K8s pods are unable to process the message, then the message will be routed back to EC2.
Going through a migration is quite a daunting feat at first, but as long as you make sure that every failure has a backup system to handle said failure and identify all the pain points that could cause data loss, every migration should go off without failure! But not without stress I’m afraid. This was only an analytical view from a broker’s perspective and applications connected to it, there are of course more complication to consider such as network, capacity planning, costs etc. But I find this one not talked about enough as we move away from centralized system and into distributed ones.