
Introduction
Have you ever removed a file with rm [FILENAME] or even worse rm -rf [DIR] only to find out that that you didn't have a backup?. Well, this happened to me with a project I hadn't pushed to Github, and could not recover despite my best efforts. Colloquially, I know that the file wasn't really deleted, it was just stored in unallocated spaces and the pointers from the file system data structures were no longer pointing to it, so the file was recoverable but I didn't know how to get it back. This post documents my journey into file system in Linux to recover files in this state. Before moving forward, please note that there is a difference between removing a file using rm and zeroing out the disk (dd if=/dev/zero of=/dev/sda). To my knowledge, data that's been zero wiped cannot be recovered by standard means (unless you are some sort of 3 letter government agency) - on magnetic disks you could probably do some magnetic ghosting. However, on most modern disks, this is (as far as I know) impossible.
Prerequisites
- Linux Machine
- ext4 File System
- The Sluth Kit (TSK: https://www.sleuthkit.org/)
sudo apt-get install sleuthkit
My Setup
I have a nvm disk and a default installation of Linux, which means I have two partitions, the boot partition and the rest of the disk is used as data blocks.
$ /Forensics/recovery lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 477G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/efi
└─nvme0n1p2 259:2 0 476,4G 0 part /And to see how it is mounted on the file system:
$ /Forensics/recovery df -h
Filesystem Size Used Avail Use% Mounted on
udev 7,8G 0 7,8G 0% /dev
tmpfs 1,6G 2,0M 1,6G 1% /run
/dev/nvme0n1p2 468G 292G 153G 66% /Let’s Do It!
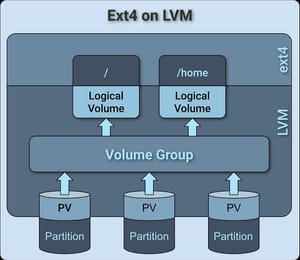
In Linux, the default fileystem is ext4, and most often than not, LVM is being used, so the abstraction model for a typical Debian based Linux system could be summarized as follows:
Disk (Physical) -> Partition (Logical) -> LVM -> Filesystem (Ext4) -> Block DataThat’s how a disk should look in your mind, but to actual OS, it doesn’t care about anything but iNodes: paths and directories are irrelevant — all it cares about is the disk and the iNode number, you can view the iNode of any file or directory by running ls -i
$ /Forensics/recovery ls -i
total 16
24126926 drwxrwxr-x 2 danielftapiar danielftapiar 4096 may 24 12:18 .
24126166 drwxrwxr-x 5 danielftapiar danielftapiar 4096 may 24 12:15 ..
24126928 -rw-rw-r-- 1 danielftapiar danielftapiar 48 may 24 12:18 veryImportantFile2.txt
24126927 -rw-rw-r-- 1 danielftapiar danielftapiar 58 may 24 12:16 veryImportantFile.txt
$ /Forensics/recovery cat veryImportantFile.txt
This has some important data that cannot ever be deleted!As you can see, we have iNode numbers for the current directory at 24126926 and the following 2 files as consecutive numbers of 24126927 and 24126928 . This is important later on.
Every block size on a default ext4 system is 4096[Kb]
TSK: The Sleuth Kit
TSK is a suite for forensic analysis on a file system, it will be used across this experiment to view the internals of the disk and file system, First let’s get some information on our current file system and disk /dev/nvme0n1p2 (yours could be different).
$ sudo su
$ fsstat /dev/nvme0n1p2
File System Type: Ext4
Volume Name:
Volume ID: 130baa837c7eea8de64ea08eca2e1ab9
Last Written at: 2020-05-21 22:57:26 (-04)
Last Checked at: 2019-09-17 23:56:46 (-03)
Last Mounted at: 2020-05-21 22:57:26 (-04)
Unmounted properly
Last mounted on: /
Source OS: Linux
Dynamic Structure
Compat Features: Journal, Ext Attributes, Resize Inode, Dir Index
InCompat Features: Filetype, Needs Recovery, Extents, 64bit, Flexible Block Groups,
Read Only Compat Features: Sparse Super, Large File, Huge File, Extra Inode Size
Journal ID: 00
Journal Inode: 8
METADATA INFORMATION
--------------------------------------------
Inode Range: 1 - 31227905
Root Directory: 2
Free Inodes: 30133037
Inode Size: 256
Orphan Inodes: 14326396, 14316784, 24641539, 14291343, 23199801, 14330335, 23199879, 14325278, 14320613, 14294096, 14290435, 14292001, 15337327, 23199747,
CONTENT INFORMATION
--------------------------------------------
Block Groups Per Flex Group: 16
Block Range: 0 - 124895487
Block Size: 4096
Free Blocks: 53805922
BLOCK GROUP INFORMATION
--------------------------------------------
Number of Block Groups: 3812
Inodes per group: 8192
Blocks per group: 32768
Group: 0:
Block Group Flags: [INODE_ZEROED]
Inode Range: 1 - 8192
Block Range: 0 - 32767
Layout:
Super Block: 0 - 0
Group Descriptor Table: 1 - 60
Group Descriptor Growth Blocks: 61 - 1084
Data bitmap: 1085 - 1085
Inode bitmap: 1101 - 1101
Inode Table: 1117 - 1628
Data Blocks: 9309 - 32767
Free Inodes: 8175 (99%)
Free Blocks: 9124 (27%)
Total Directories: 2
Stored Checksum: 0x4CF0
...This gives us a low level overview of the file system, a Block size of 4096 [Kb] how many free blocks are remaining, iNodes per group (8192) and blocks per groups (32768)
The theory behind data recovery is that the files aren’t really deleted, just the pointers from the file system data structures. The deleted blocks that accommodated the files are still there, but are now marked as UNALLOCATED - which means that it is available to be overwritten by incoming writes to disk. Therefore, it is very important if you just noticed that you've deleted critical data then you should stop all writes to the target system. This means: kill all processes that are writing new data to disk or the most, turning off the target machine.
The technique I’ll be using is disk carving, which means that I will use dd as a sort of scalpel to carve out sections of the disk that we know was the previous location of our lost data. So in our previous example we had iNode numbers 24126926, 24126927, 24126928, it has to be mapped to the correct Block Group number, to figure this out we need the iNode range (8192) and the iNode number of the deleted files.
$ echo $(( 24126926 / 8192 ))
2945So around Group Block 2945, we should have our iNode range, let’s verify:
$ fsstat /dev/nvme0n1p2 | grep "Group: 2945" -A12
Group: 2945:
Block Group Flags: [INODE_ZEROED]
Inode Range: 24125441 - 24133632
Block Range: 96501760 - 96534527
Layout:
Data bitmap: 96468993 - 96468993
Inode bitmap: 96469009 - 96469009
Inode Table: 96469536 - 96470047
Data Blocks: 96501760 - 96534527
Free Inodes: 6679 (81%)
Free Blocks: 0 (0%)
Total Directories: 129
Stored Checksum: 0x1FEFOur iNodes are in the range, which means that we can get our data from this block, run dd as follows:
$ dd if=/dev/nvme0n1p2 bs=4096 skip=96501760 count=32767 of=./images/bg2945.raw
32767+0 records in
32767+0 records out
134213632 bytes (134 MB, 128 MiB) copied, 0,214837 s, 625 MB/sbs: block group size (4096 [Kb])skip: number of block groups to skip (Group 2945 starts at 96501760)count: number of bytes from offset (96534527 - 96501760, eg: The entire block group)if: input file, from which file (in this case block device), to use as inputof: output file, where to store the image
And now looking for strings in this image, we should see our current file,
$ root@earth:/Forensics/recovery# strings images/bg2945.raw | grep "This has some important data that cannot ever be deleted!"
This has some important data that cannot ever be deleted!So we carved out the file, that is present on the filesystem but it was never deleted, if it is deleted now, then run the same chain of commands we can recover the file.
$ rm veryImportantFile.txt
$ dd if=/dev/nvme0n1p2 bs=4096 skip=96501760 count=32767 of=./images/bg2945.raw
$ strings images/bg2945.raw | grep "This has some important data that cannot ever be deleted!"
This has some important data that cannot ever be deleted!And boom! The file is in the image and you can view the contents to your heart’s content by using dd and outputting it to a file.
Magic numbers
To view the contents of your file depends a lot on the type of file that was deleted and how you carve it, Because carving tools such as dd do not rely on the file system, they need other sources of information to discover where a file starts and ends. Fortunately, many file types have known structures. The header and footer are often all that is needed to identify the file type and location. The Linux file command also uses header and footer information to identify file types. Using dd in the same manner as before but targeting the header and footer of your missing file and outputing that to a file is all that is needed. The header or signature of these blocks are called magic numbers and they help identify the file type, and how long the block is.
Images for example have known magic numbers, JPEG starts with byte sequence 0xFFD8 and often followed by 0xFFE00010 where as word documents start with 0x504B0304 along with 0x14000600 . You can view the list here
Odd Cases
There are times when the block is carved and the file isn’t there, most of the time the file system places the files in the same block as the parent directory. If not, it will attempt to place it in the adjacent block and so forth, so when carving the file system with dd instead of targeting count with the block size you might want to multiply that value by however many blocks you want to look forward, so count=BLOCKSIZE*NUMBER_OF_BLOCKS and look for your file there.
There are other times when the disk is full and the file is placed at the very edges of the disk. This happened to me when I was actually trying to dump an image on my file system and it was bigger than I expected and in turn used up 100% of the disk. Thus, any new files were placed anywhere the file system could fit it. the adjacent block placement didn’t work in this case. I had to resort to create a random file using touch then executing istat to get the Direct Block it was created.
$ istat /dev/nvme0n1p2 24126929
inode: 24126929
Allocated
Group: 2945
Generation Id: 754060831
uid / gid: 1000 / 1000
mode: rrw-rw-r--
Flags: Extents,
size: 58
num of links: 1
Inode Times:
Accessed: 2020-05-24 12:16:52.796495865 (-04)
File Modified: 2020-05-24 12:16:49.344420627 (-04)
Inode Modified: 2020-05-24 12:16:49.344420627 (-04)
File Created: 2020-05-24 12:16:14.503635323 (-04)
Direct Blocks:
57818842In this case Direct Block: 57818842, which is way farther than my previous attempt. This gives me a ball park estimate as to where to start the carving with dd to get to a recently created file that was deleted on a file system that had had its file system filled.