

This is part 2 of my series on Migrating from AWS to GCP. We break up the problem into three domains of Network, Application and Databases. You can view Part 1 here where we discuss the network plane. In this post, we cover the Application domain.
Introduction
In reality, the amount of work involved in this phase will depend on how good the design of your existing systems are and how well they follow the SDLC best practices. It also depends on how much your existing infrastructure and application code are tied to the cloud provider you currently use, e.g. AWS in this case. We don’t necessarily consider this as ‘bad practice’; writing code with specific cloud SDKs often makes sense in the normal course of business. Though, it can and will make migration more difficult.
People rarely think about portability of their software between cloud providers until…well… when they need to. And arguably that’s how it should be, as otherwise it will unnecessarily prolong the development lifecycle for not much daily business gain.
It’s outside the scope of this post to go through those challenges in detail because our job is to focus on the infrastructure components. We’ll briefly touch on the high levels of microservice design practices and also glance over Infrastructure-as-Code (IaC) changes between providers, but that’s about it. That said, we aim to publish a separate series on software design patterns including Microservices and what you as a Cloud Engineer need to be aware of to be effective in those conversations, so stay tuned!
The good, the bad…
As said above, ideally micro service design patterns and practices are followed in your existing infrastructure. For instance:
- Config management is separate to code and handled using Environment Variables. This is important for portability of the software and means you can reuse the same container image / deployment blueprint and would just have to update their config to point to the new systems (in this case in GCP for example).
- Services are self-contained and have no hard dependencies on each other (or at least that’s kept to a reasonable minimum) — this helps distributing and “parallelising” the migration workload across different teams/owners as opposed to creating huge dependency trees and waterfall planning models with long “Blocked” cycles.
- Services are stateless, meaning they can be hosted in ephemeral containers that can go up and down while still able to restore their previous state. This makes transitioning easier since a new service can be brought up in either environments without worrying about maintaining a consistent state. However, over-engineered caching or peculiar I/O usage patterns may complicate things. Or for instance, connection pools and their interaction with infrastructure components such as brokers (RabbitMQ and Kafka differ on this) should be analyzed carefully, as adding consumer groups to these components can cause re-balancing of queues or consumer groups. A good litmus test for statelessness and portability of the systems is to randomly kill their pods and verify that the application continues to work as expected.
- Logs should be streamed to
STDOUTand ideally in a JSON format instead of a local log file. This makes it easier to switch between cloud providers like GCP and AWS's Cloud Logging and CloudWatch, which read from their nodes' STDOUT and forward the logs into their logging systems. By doing this, logging becomes more portable and decoupled from the underlying driver, resulting in a more unified transition experience.
If you’re more interested in the design aspects of micro services, we recommend checking out https://12factor.net/.
Challenges:
When speaking of challenges of migrating an application from a cloud provider to another, we find it useful to once define the phases involved so that we can refer to them elsewhere.
Phases
- Planning: Allocating resources, high-level commercial decision making, understanding the problems, etc.
- Design and Architect: White boarding and visualizing the system components, both in current state and in target state (likely to be at least slightly different)
- Implementation — deployment of independent internal (non or low customer-facing) resources into the new environment such provisioning of repositories, IAM permissions, VPN Tunnels etc.
- Transition: Switch the DNS to allow all or partial traffic from one cloud provider to the other.
- Verification and Testing: Once traffic is flowing into the new system, run tests for stability and do a checklist on all services to verify their application and database metrics.
- Cleanup and Decommission: Once the app has been successfully migrated over, delete resources on the old cloud provider.
In addition to the difficult software practice / process challenges mentioned in the previous section, you’ll likely also face certain challenges to do with the infrastructure components backing your application services, particularly during the Transition phase. We cover each of the following in more depth in the following sections.
- Message Broker Consistency: most modern distributed architectures in one way or another use message brokers and/or a streaming layer to decouple event producers and consumers. If this happens to also be the case in your stack, you’d need to carefully think about your inflight events. For instance how the messages in the AWS broker are going to also be replicated and consumed by the one in the GCP site (and how that could impact application state). In our case this happened to RabbitMQ but the same could be discussed for Kafka, Solace, etc. clusters.
- Distributed Caching Systems: Moving over standalone or distributed caches from AWS → GCP; in our case this was a Redis Cluster.
- Custom cloud components: AWS resources such as Lambdas, Secrets, KMS keys and many more will not be seamlessly reusable in GCP.
- Partial hostname resolution to GCP infrastructure: In this case when we had all the microservices that made up the application deployed, we wanted to experiment with small functionality that involved 1 microservices from AWS and route the request to 2 other GCP services, for integration testing.
Brokers: RabbitMQ
If your infrastructure is composed of message brokers, and depending on various things, such as: how quickly your platform can consume the messages in the queue, you may run into the problem of handling multiple / simultaneous consumers which could lead to splits and missing events in the brokers involved:
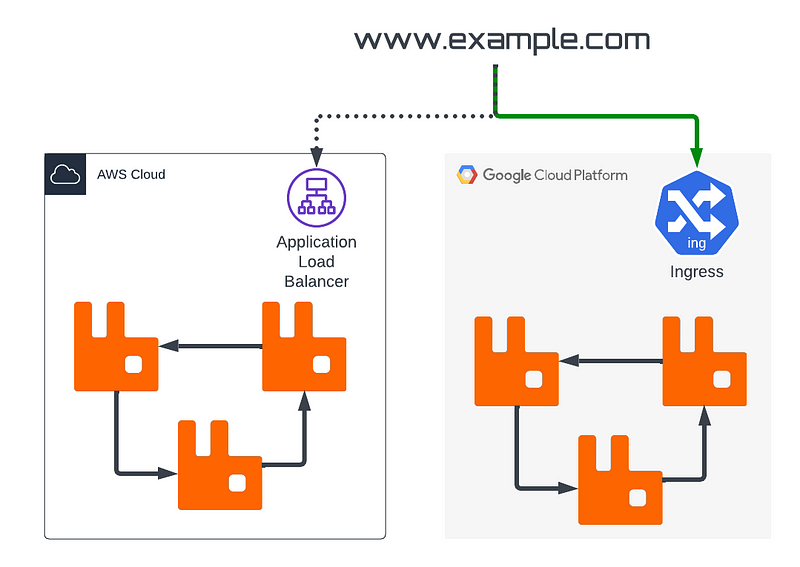
During DNS cutover, there may still exist queues that contain unacknowledged messages, which in turn are fundamentally important to your data integrity and should be carefully evaluated. Thankfully there are tools such as RabbitMQ’s shovel plugin that can move the content of queues from one cluster to another
Docs: A shovel behaves like a well-written client application, which connects to its source and destination, consumes and republishes messages, and uses acknowledgements on both ends to cope with failures.
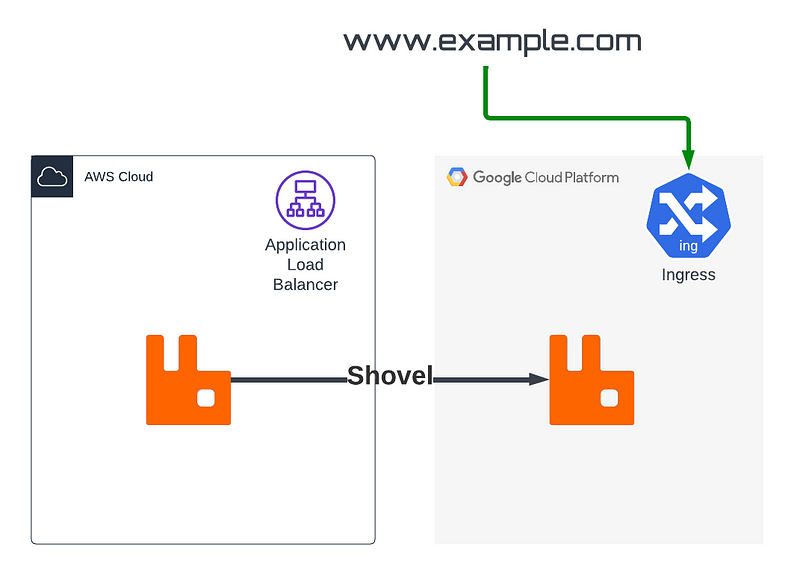
This is only possible by leveraging the VPN connection between the two cloud providers so making sure that you’ve done the VPN connection on the network side is crucial, as well as hostname resolution.
Mirroring
Another solution we tried with RabbitMQ was mirroring the queues across cloud providers, which had much heavier resource usage than we thought — and it scales with volume. This has the potential to collide with RabbitMQ’s high watermark breaks which lead to it dropping all connections to the broker (beyond 40% memory usage); note this doesn’t cause RabbitMQ to stop working altogether, but it will throttle the publishing of new messages until memory usage goes below the watermark again. This is due to Erlang’s garbage collector mechanism, bringing memory usage up to 80% thus causing the broker to fail, you can read more about it here. In the end we decided to go with the first approach of shovelling the messages after cutover since it provided more stability and better performance, and also because some loss of data integrity was not a major issue during our particular migration.
Caches: Redis
The cache shouldn’t have the data integrity issue that brokers have since they are meant to be ephemeral and should not be affected by the cut over and re-cache of the redis cluster on the GCP side of things. Some companies use redis as an actual database and data loss isn’t tolerable during this migration. this wasn’t an issue as the application wasn’t transactional and data loss was tolerable. but as long as you have connectivity between two redis servers you can code a simple script to migrate data between the two servers, simple dump and restore script should do the trick.
Custom Components (Serverless)
Moving AWS Lambda Functions to GCP Cloud-Functions or vice-versa could be a challenge depending on whether or not you use a framework such as the Serverless Framework to manage the functions and map its resources to the handlers. If you find yourself in the first scenario either by manually deploying and editing serverless functions or managing them in terraform, chances are you’ll find yourself with a fair amount of work in finding a way to map things to to GCP.
In the second scenario, if you’ve built your application using the serverless framework, migrating over can be as easy as copying the serverless.yml file and changing the provider. Though keep in mind, it’s not always a one line change as some plugins that your serverless application uses will probably not be available on another cloud provider so some work and refactoring of code will need to take place. The relationship between infrastructure components and application functions will however remain. Check the difference between the provider block, but the functions block still remains the same.
service: hello-world-google
provider:
name: google
runtime: nodejs14
project: your-gcp-project
credentials: ~/.gcp/keyfile.json
plugins:
- serverless-google-cloudfunctions
functions:
hello:
handler: handler.hello
events:
- http: hello
path: hello
method: getservice: hello-world-aws
provider:
name: aws
runtime: nodejs14.x
region: us-east-1
plugins:
- some-plugin-aws
functions:
hello:
handler: handler.hello
events:
- http:
path: hello
method: getTerraform
When migrating applications that have resources managed in Infrastructure As Code (IaC), you likely will not be able to easily translate from one provider to another; take a look at the following resource blocks from terraform for a lambda function in AWS and contrast it with a GCP Cloud Function.
resource "aws_lambda_function" "test_lambda" {
filename = "lambda_function_payload.zip"
function_name = "lambda_function_name"
role = aws_iam_role.iam_for_lambda.arn
handler = "index.test"
source_code_hash = data.archive_file.lambda.output_base64sha256
runtime = "nodejs16.x"
environment {
variables = {
foo = "bar"
}
}
}resource "google_cloudfunctions_function" "function" {
name = "function-test"
description = "My function"
runtime = "nodejs16"
available_memory_mb = 128
source_archive_bucket = google_storage_bucket.bucket.name
source_archive_object = google_storage_bucket_object.archive.name
trigger_http = true
entry_point = "helloGET"
}As we can see, there is very little overlap between terraform arguments to the resources they map to, not to mention that these resources are usually tied together with IAM/Role Permissions, Triggers and/or Layers (Step Functions in AWS). All of those resources are not a 1–1 translation and would require more focused and individual work rather than a batch process.
Partial Routing of Request via Hostnames
In order to test your application during the migration, you need to have a subdomain that is easily configurable that allows you to know and test which endpoints to which cloud and you can run tests in isolation from each other. Let’s imagine a User Service that wants to know what permissions it has available to it, to do this it must call another service called the Role Service and this in turn calls the Permission Service, and since we are doing a migration we have to deploy this setup on both cloud providers as illustrated below.
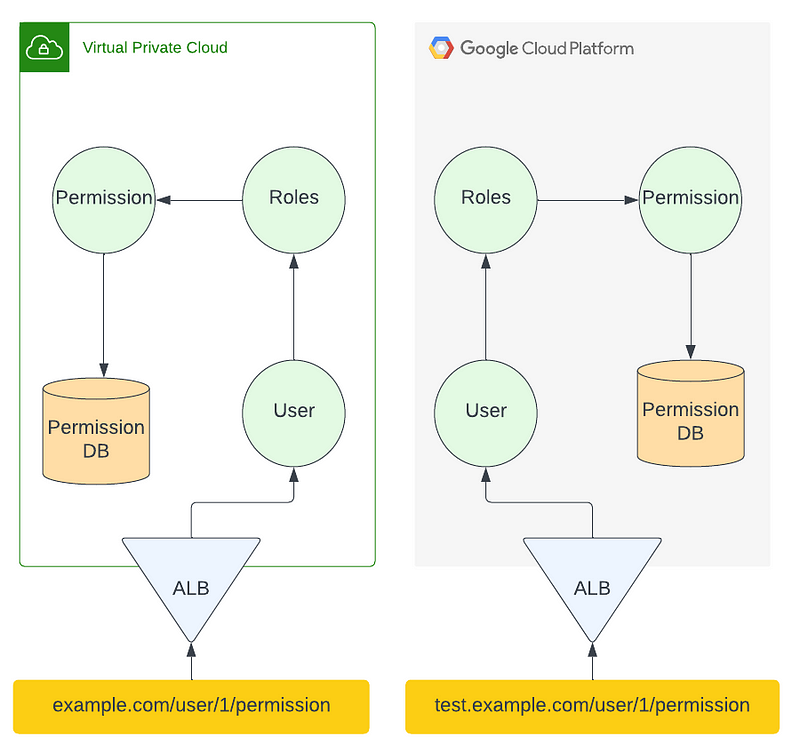
Issues can arise if you want to just test a service from the analogous cluster in GCP that is not live against a production service in AWS. This would be before DNS cutover as you are testing your incoming GCP cluster against what is already working in AWS.
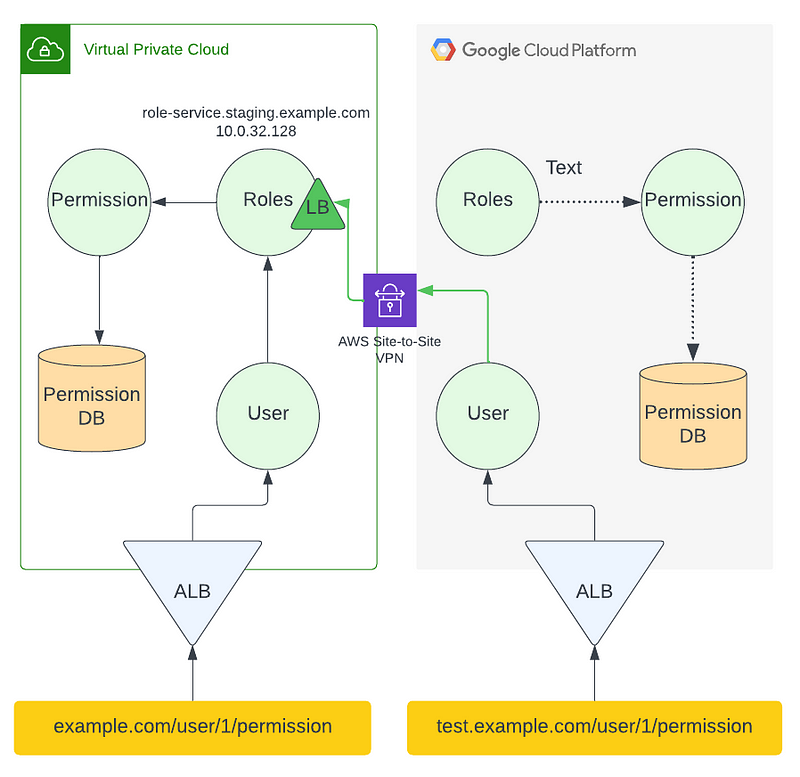
To do this, your application must have a way of configuring the endpoints of (in this case) the user service must have in its configuration an environment variable or application properties that allows it to target the role service. This where the external DNS that we deployed on Part 1 comes into play, the Role Service in GCP will be fronted by a LoadBalancer exposing a routable IP and an A Record in CloudDNS. At this step, you can configure your user service on GCP to point to Role Service in AWS by IP if you don’t want to deal with DNS.
# .env file for your service
ROLE_SERVICE=role-service.staging.example.com # Internal DNS
ROLE_SERVICE=10.0.32.128 # or...IP of the Internal Load Balancer forIn the case that you do want to route by hostnames and DNS, you will need to configure DNS forwarders on Route53 or CloudDNS, this article explains the process in detail.
Once this is set up correctly, you can restart your application with different hostname configuration to test out different route paths in an isolated manner.
Conclusion
You can find Part 3 here, where we’ll talk about database infrastructure components and the challenges that we faced when migrating them over and how we solved it.