

Introduction
I’ve been working with kubernetes for over 6 years and one of the questions that has always intrigued me, is how exactly does the CPU function in a containerized environment. Not for instance in terms of kubelet and the K8s components, as this has been explained in great detail in many other posts, but rather in terms of actual threads and lower level components; how does this affect scheduling? Is this even worth learning in 2023? With the rise of Artificial Intelligence where everyone keeps talking about GPUs, do CPUs have a place in the future?
As we shall see, turns out that even in the new AI world order, certain use cases would still heavily rely on CPU; algorithm-intensive tasks that don’t support parallel processing such as real-time inference and machine learning (ML) algorithms that don’t parallelize easily being a couple of examples. Therefore there is still value in learning how all this stuff works. And since Kubernetes is at the forefront of MLOPS, let’s look at this simple example of k8s pod manifest and dive in:
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "128Mi"
cpu: "1"What is this and how does it map to the underlying hardware? How does this stuff correlate with performance of the container and the host? Should we use limits? Is there a trade off with having too many pods in a single node? How is thread performance visualized? Well let’s explore these questions.
Hardware Threads
The first component is the processor, try running this command:
$ cat /proc/cpuinfo | grep "model name" | uniq
model name : 12th Gen Intel(R) Core(TM) i9-12900HAs you can tell my machine has an Intel Processor. Now according to Intel’s specs and CPU Specifications for that particular model, I have:
Total Cores: 14
# of Performance-cores: 6
# of Efficient-cores: 8
Total Threads: 20Let’s break this down and see if we can figure out what this means:
$ lscpu | grep -E '^Thread|^Core|^Socket|^CPU\\('
CPU(s): 20
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 1From this we can infer that lscpu correctly shows that I only have 1 processor socket on my laptop, it also aligns CPU(s) with Intel’s Total Threads at 20 and Total Cores aligns with Core(s) per socket at 14, but the other values of Performance-cores and Efficient-cores are not shown by lscpu , this is because the lscpu doesn’t see the difference between a performance or efficient core, it just sees core as presented by the OS.
You can read more about P-cores and E-cores here , in terms of threading, for our purposes we mainly care about this.
P-cores also offer hyper threading, meaning each core will have two processing threads for tackling loads better.
This means that P-cores have 2 threads per core and E-cores have 1 per core, armed with this information we can now make the numbers align
(# of Performance-cores) x 2 + (# of Efficient-cores) x 1
6 x 2 + 8 x 1 = 20This means that the OS recognizes each hardware thread as a different CPU or virtual core (vCpu). This means that my particular Processor can execute in parallel 20 hardware threads.
Be careful when choosing the machine type to run your workloads, when deploying on kubernetes you don’t choose which cores (p or e) run your workloads. CPU pinning helps on this regard as you can tie a container to a CPU core for target execution, If you run an Intel workload. Scheduling on an e-core is not the same as scheduling on a p-core, 5[ms] of execution time on an e-core running at lower clock speed has less cpu cycles than a p-core and can make workloads not perform as expected.
Operating System Threads
Software threads are a software abstraction implemented by the (Linux) kernel. Software threads are abstraction to the hardware to make multi-processing possible
One hardware thread can run many software threads. In modern operating systems, this is often done by time-slicing — each thread gets a few milliseconds to execute before the OS schedules another thread to run on that CPU. Since the OS switches back and forth between the threads quickly, it appears as if one CPU is doing more than one thing at once, but in reality, a core is still running only one hardware thread, which switches between many software threads.
There is a lot of confusion when delving into this topic on what exactly does a core mean? as we saw from the images, 1 thread is registered as a core by the operating system they aren’t really actual physical cores. It’s just another abstraction, later you’ll find out that threads viewed in this manner isn’t really what’s going on under the hood, but rather the time slices and windows of execution within a core that matters.
Software Threads
When your program creates a thread, that is a software thread. Think of it like creating work for the CPU. The software thread is created between you and the OS. The CPU hardware is not involved into this transaction yet. Only you and the OS. In Java this is done via the Thread Class.
public static void main(String[] argv){
Thread t = new Thread();
t.start();
}Threads can be sleeping, or active. If a thread is sleeping, it’s in the OS, but it’s not being scheduled. As in, it’s just waiting. If it’s active, then the OS puts it in the scheduler pool. From there, the scheduler picks 20 threads to run in the next cycle, roughly every 16 ms. The 20 threads being picked, will be equal to the number of CPU threads on this particular system. So you have a scheduler pool (called CFS: Completely Fair Scheduler) with 0 to 10,000 active threads, and the OS picks 20 of them to run in the next cycle, because you have a 20 Hardware thread CPU. These hardware threads, consume the processing work created in the program.
So, Software threads = work created by your program.
Hardware threads = units that consume software threads.
You can schedule 1,000 pies to be eaten, but since the CPU has 20 mouths to eat, it will eat those pies 20 at a time.
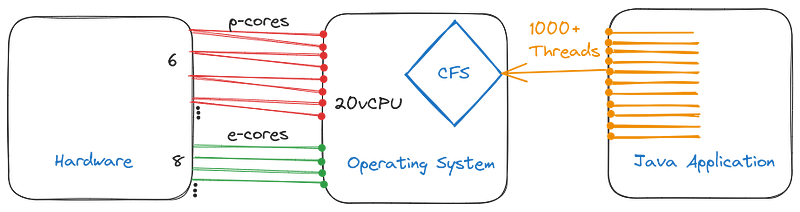
Now you can’t really go crazy on the thread creation as a single JVM thread by default will require 1[Mb] of Memory, which means that if we have 1000 threads on the jvm around 1Gb of memory to maintain those threads.
Having too many threads also causes context switch overhead, what this means is that every 100[ms] a thread is pulled out of the core, its state is saved and a new thread is scheduled in its place, this is done to allow all processes in the system a chance to execute according to the kernel’s CFS algorithm.
This process is more expensive if the thread doesn’t belong to the same process as context switches between threads of the same process share the same process resources, which is why you’ll see lots of threads per processes.
In the same example, if we have 1000 threads we will have a lot of context switch, and overhead, which translates to roughly 5[μs] or 0.005[ms], per context switch, and it could be worse if there are cache misses. If you have a 1000 threads context switching that would translate to 5[ms] an entire time slice window of cpu execution!.
Having too many threads, paradoxically decreases throughput, how? Well if we have 1000 threads then the scheduler has to juggle the start and sleep of these threads as well as them competing over the same hardware resources, stressing the system. This increase in thread context switching leads to wiping of caches since we will be constantly clearing and populating cache values as well as increasing the chances of deadlock A good choice here is to limit the number of threads to the number of cores on given machine.
On a final note specially speaking to java world, every jvm thread is a root of GC Process, so by having a large number of jvm threads we might increase the time it takes to garbage collect our application.
Containers in Kubernetes
Well this is all fine and good but what does it have to do with containers? Well…practically everything, all this talk of threads on a non containerized workload also applies to containers or pods within Kubernetes. The only distinction is how it is applied, containers are nothing more than kernel features applied in multiple domains such as processes, file system, hosts etc.
On kuberentes having too many threads can cause issues, the most common one is failing health checks due to cpu limits placed on the container by the pod spec’s request block, pods going over this limit will fail to respond causing the pod to start a CrashBackLoop error which is a major pain to debug.
The kubernetes component that reads a resource block from the PodSpec is called kubelet , then it passes it on to the Container Runtime Interface such as containerd or crio-o , to finally give it the container runtime such as runc (I talk about this process in another post if you are interested). It is only when you are dealing with container runtimes when you’ll start seeing mentions of cgroups. Understanding these kernel components and how they can relate to threads is critical to continue our journey.
CFS
As stated previously, the Completely Fair Scheduler (CFS) in the Linux kernel is responsible for thread scheduling and CPU resource allocation. When a process requests CPU resources, CFS assigns it a proportion of the CPU time based on the amount of CPU time the process has already consumed and the overall workload on the system. CFS can be tuned to support relative minimum resources as well as hard-ceiling enforcement used to cap processes from using more resources than provisioned, such as CPU limits in kubernetes pod specs.
CFS also has a burst feature built into its scheduling algorithm to allow a container to accumulate CPU time when the container is idle. The container can use the accumulated CPU time to burst above cpu limit when the CPU usage spikes. This is feature is leveraged by services such as Koordinator which modify the CFS limits in cgroups without modifying the pod spec of the pod, which adds to the mysticism of a Kubernetes environment.
Control Groups V2
Control Groups cgroup is a Linux kernel feature that is used to limit and isolate resource usage of a group of processes and it is where all the magic happens, every piece of software on kubernetes that manages cpu is built on top of this and it is critical to understanding our threading woes.
On a Debian system, you can use the cgroup2 filesystem to manage cgroups V2. The cgroup2 filesystem is mounted at /sys/fs/cgroup.
Any folders within the /sys/fs/cgroup can be thought of children of the main root control group so if you are trying to find say… the docker cgroup files you can look at your docker system to see your container ids, these are isolated using cgroups so it’s a good exercise to find them in your system.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c9faa5a77b67 influxdb:latest "/entrypoint.sh infl…" 2 weeks ago Up 26 hours 0.0.0.0:8086->8086/tcp, :::8086->8086/tcp influxdb
a60e5a2b1534 mysql:5.7 "docker-entrypoint.s…" 3 weeks ago Up 26 hours 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp mysql
8fa221963b34 postgres:14.1-alpine "docker-entrypoint.s…" 2 months ago Up 26 hours 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp postgresYou can run systemd-cglsit will give you the tree view of all control groups on your system.
output "vpc" {
# value = local.vpc
# }$ systemd-cgls
Control group /:
-.slice
├─user.slice
│ └─user-1000.slice
│
├─init.scope
│ └─1 /sbin/init splash
└─system.slice
├─docker.service
│ ├─1551 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.so…
│ ├─1981 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 5432 -c…
│ ├─1988 /usr/bin/docker-proxy -proto tcp -host-ip :: -host-port 5432 -contai…
│ ├─2007 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8086 -c…
│ ├─2014 /usr/bin/docker-proxy -proto tcp -host-ip :: -host-port 8086 -contai…
│ ├─2046 /usr/bin/docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 3306 -c…
│ └─2053 /usr/bin/docker-proxy -proto tcp -host-ip :: -host-port 3306 -contai…If you are like me then probably a more visual representation makes more sense.
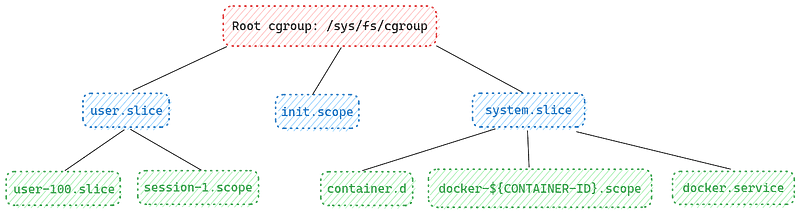
From here you can see that docker uses the folder docker-${CONTAINER-ID}-scope to isolate the container process. Kubernetes uses the kubepods cgroup.
Within these cgroups you can find many more configurations such as memory and metrics, it isn’t the point of this post to delve too deep on those topics, as we are just focusing on kernel components.
Conclusion
This is all the high-level knowledge we require to start looking at actual running processes and see how the limits placed on the pod spec affect the execution and how the CFS scheduler can throttle processes and how we can avoid them. Now there are still a few more specifics to investigate, but that would be too long of a read, so I’ll share that on the next post, which is more analysis rather than theory.