


TL;DR
An Agent’s function calling execution capability heavily depends on the underlying model.
LLM Function Calling Overview
When it comes to function calling in large language models (LLMs), the ability of a model to accurately respond to a function call request based on input prompts is absolutely crucial. In our experiments, we’ve seen how testing the same prompt across different models can lead to significantly varied results, which really highlight the importance of choosing the right model.
UC Berkeley recently released a function calling leaderboard, where the top-performing GPT-4 model achieves an accuracy rate of 85.65% (as of 28 Aug 2024).

That’s impressive, but let’s be honest — it’s still not where we need it to be for business requirements.
Unfortunately, developers have limited control over an LLM’s function calling capabilities. Even with precise definitions of API functions, parameter names, and descriptions — often well-documented by model providers — there are still challenges.
- OpenAI’s function calling guide: OpenAI Platform
- Google’s function calling guide: Google Cloud Function Calling
- Anthropic’s function calling guide: Tool use (function calling) — Anthropic
Given that execution accuracy remains less than perfect — topping at around 85.65% as per above — , this kind of inaccuracy is simply not acceptable for many business needs. That’s why it’s so important to have fallback strategies in place when function calling doesn’t go as planned. For example:
- Redirecting to human support in customer service scenarios.
- Translating API error messages into language that’s easy for users to understand and act on
In Chapter 1 of our proposed Multi-agent Framework, we talked about how an agent should be designed with a specific-enough task in mind to perform well. In this article, we — my colleague Eisha, and I — stick to that principle, and share our experiment with function calling, which we built as part of a Proof of Concept (PoC) for a recent collaboration project. We’ll also walk you through what we like to call the Agent Development Life Cycle, covering everything from gathering requirements to creating a ChatBot powered by an AI agent. We hope you’ll enjoy this journey with us.
Requirement & Design
The overall platform requirement was fairly substantial, we therefore attempted to break it into smaller domains and deliverables. One specific task was to build an API that allows users to find schools given a location, starting with UK postcodes. To make the agent’s task specific enough, we decided to use just one function. Here’s the design:
- A dataset containing schools and their geolocation.
- A function that takes the geolocation and finds schools in the dataset.
- An AI Agent that handles user input for school search and calls the function to generate responses.
Implementation
We sourced datasets (such as schools data and postcode-to-coordinate data, from UK government public data repositories), then built a data pipeline to process the required data. We used SQLMesh for the data pipeline and DuckDB as the database. Here’s a glimpse of the pipeline lineage:
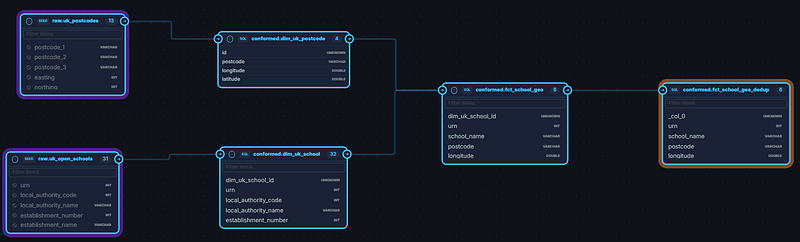
The function is straightforward: given a postcode, we convert it to coordinates, and given the coordinates, we find the closest schools and return the top N results.
from phi.tools import Toolkit
...
class SchoolSearch(Toolkit):
...
# Function to find nearest schools
def find_nearest_schools(self, postcode: str, num_neighbors: int = 5) -> dict:
"""Runs a number of neighbor's schools which close to the postcode
Args:
postcode (str): the valid UK postcode
num_neighbors (int): The number of schools will be returned, default to 5
Returns:
DataFrame: the output schools in a dict
"""
logger.info(f'Function is called {postcode}, {num_neighbors}')
file_dir = Path(__file__).parent
db_path = file_dir / 'fact.duckdb'
with db.connect(str(db_path.absolute())) as connection:
# Get coordinates for the provided postcode
user_coords = self.get_coordinates_from_postcode(postcode, connection)
logger.info(f'coords {user_coords}')
if user_coords is None or user_coords.empty:
return f"Cannot find school given postcode {postcode}"# Handle case where postcode is not found
user_lat = user_coords.iloc[0]['latitude']
user_lon = user_coords.iloc[0]['longitude']
# Get all school data
df = self.get_all_school_data(connection)
# Calculate distance for each school
df['distance'] = df.apply(lambda row: self.haversine(user_lat, user_lon, row['latitude'], row['longitude']), axis=1)
# Sort by distance and get the top N nearest schools
nearest_schools = df.sort_values(by='distance').head(num_neighbors)
return nearest_schools.to_json(orient='records')To create the Agent, here we used PhiData
from phi.assistant import Assistant
from phi.llm.openai import OpenAIChat
...
assistant = Assistant(
tools=[SchoolSearch()],
llm = OpenAIChat(model='gpt-4o-mini', api_key='<api-key>')
show_tool_calls=True
)
...We then built a FastAPI service around this agent and a simple Chatbot WebUI. Here’s a screenshot:
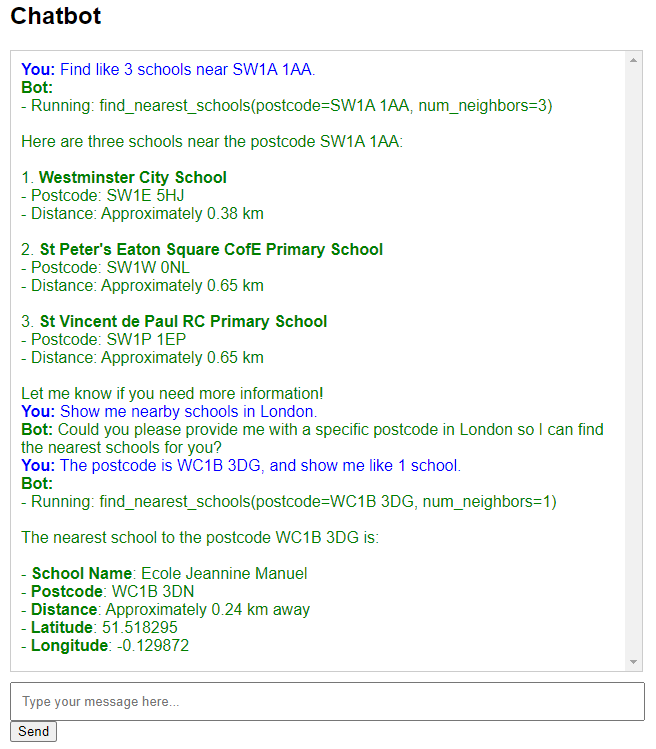
It does the job, though better prompt engineering would definitely improve responses. Now, let’s move on to the fun part — testing!
Testing and Eval
We’ll skip unit tests and jump straight into smoke testing. We’ve designed prompts and expected outputs like the following.
index,prompt,function_called,function_args_postcode,function_args_number_schools,expected_response
1,"Find like 10 schools near SW1A 1AA.",true,SW1A 1AA,10,"show nearby schools, the school number should be 10"
2,"What are the best schools around W1A.",false,,,ask user to provide the postcode instead
3,"Can you list 7 schools close to EC2N 2DB.",true,EC2N 2DB,7,"show nearby schools, the school number should be 7"
...
39,"Translate 'hello' to French.",false,,,explain to user that this agent is designed to show schools close to a postcode provided by user
40,"What's the time in New York right now.",false,,,explain to user that this agent is designed to show schools close to a postcode provided by userThe first 20 inputs focused on searching for schools, while the remaining 20 were unrelated dummy prompts. Here is the full list.
Given these prompts, we want to evaluate the agent’s performance. The agent should only respond to school search requests and reject irrelevant queries by providing helpful instructions. In smoke testing, we’ll also test different models like Openai GPT-4o, Llama 7B, and other open-source models that can run locally on my machine with Ollama. Here’s the list:
gpt-4o
gpt-4o-mini
llama3
llama3.1
llama3-groq-tool-use
phi3:medium
phi3.5
gemma2We built an evaluation function to check function calling, and using gpt-4o-mini to check if response (Return usage to user and Correct Response) was as expected. Here’s the flow:
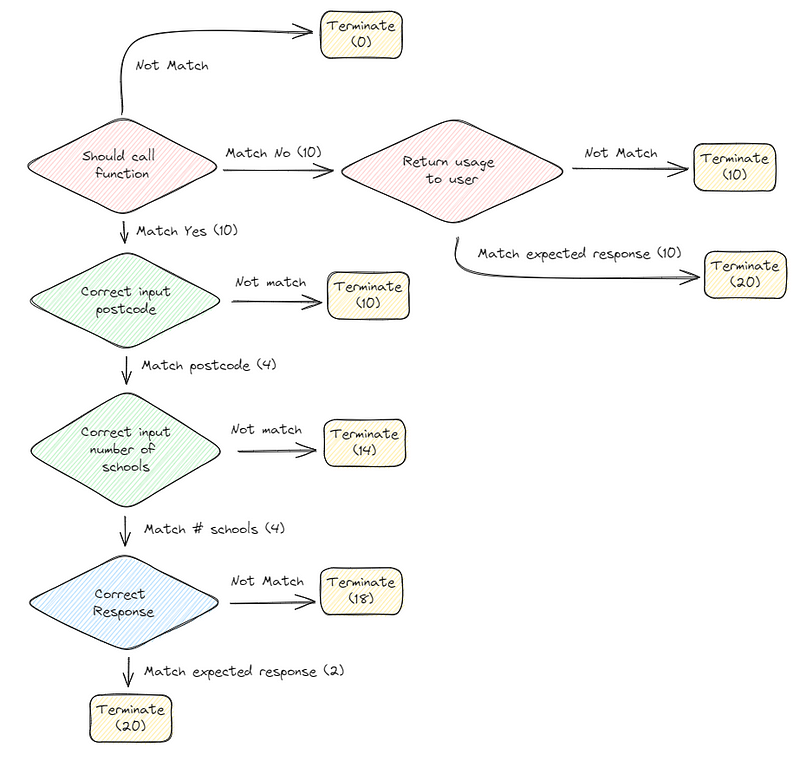
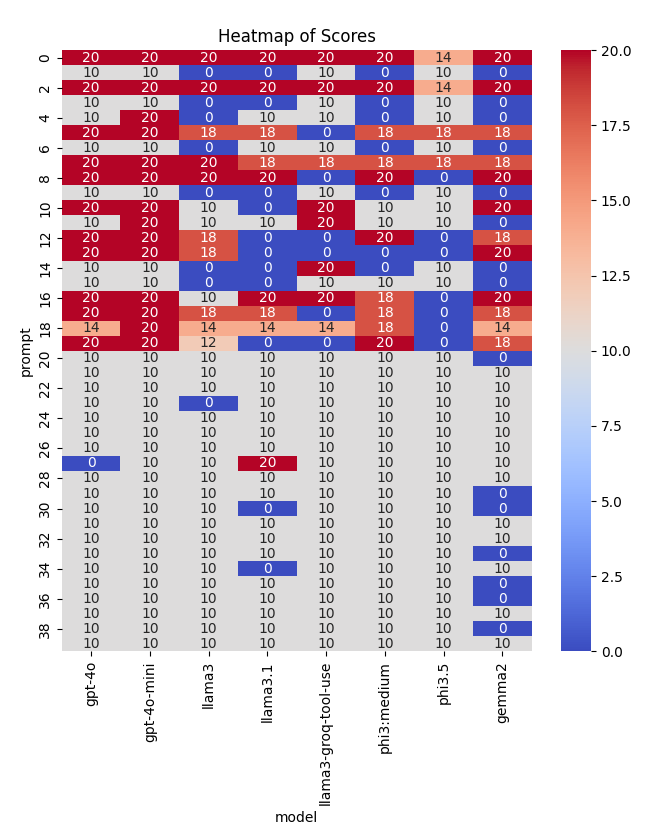
Then the result is like this
So can we improve the agent’s performance? Since we have limited control over the function call from the model, can we provide better instructions in the prompt? Here’s the updated agent description and instructions:
"description": "You help users find schools near a specific UK postcode. You process queries only when asked about schools around or near a UK postcode and responds with a list based on function call.",
"instructions": [
'Process input only if it requests information about schools around or near a UK postcode',
'Handle valid queries that contain a UK postcode or clearly indicate a need for school information based on location.',
'If the query is unclear or lacks a valid UK postcode, prompt the user to provide more information.',
'DO NOT use function calling if the query is unclear or lacks a valid UK postcode.',
'Ensure the agent only processes relevant requests and guides users on its proper usage.'
],And here is the results with prompt
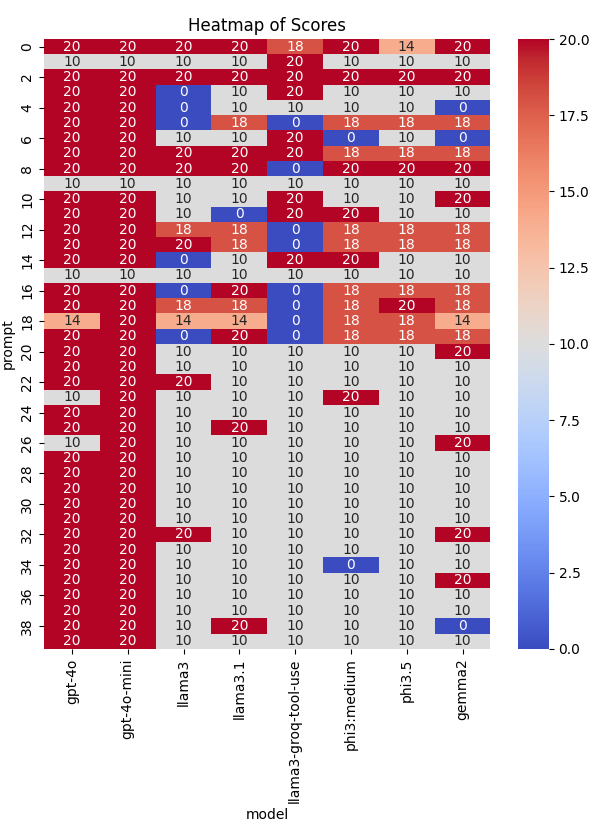
And a bar chart to compare with and without prompt:
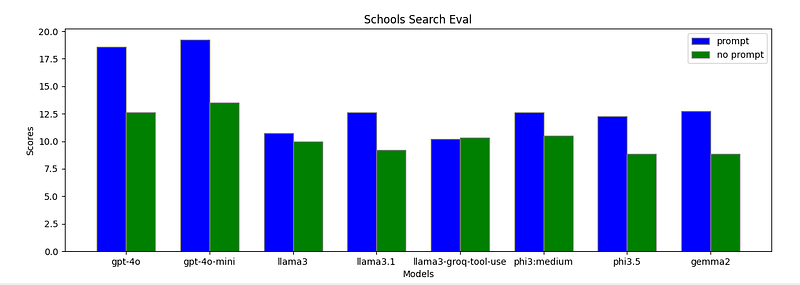
After analyzing the results ourselves, we discovered that the llama3-groq-tool-use model actually could perform better than llama3, llama3.1, phi3.5, and phi3. However, the LLM used in our evaluation function did not accurately assess the responses from the llama3-groq-tool-use model, indicating a need for further refinement in our evaluation LLM’s prompting strategy, which leads to the next round of Agent Development Life Cycle.
Since we modified some of the dependent code, it might be challenging to reproduce the setup. Therefore, we’ve built a Docker image. We simplified the code, exposed some variables, and created a docker-compose file, allowing you to try the agent we build with OpenAI GPT-4o-mini. You can run the docker compose and open a browser (http://localhost:8000/) to try the school search agent.
version: '3.8'
services:
binome-school-search-agent:
image: guanyili/binome-school-search-agent
environment:
ENV: docker
OPENAI_API_KEY: <your-openai-api-key>
ports:
- "8000:8000"
extra_hosts:
- "host.docker.internal:host-gateway"Summary
In this experiment, we detailed our journey from initial requirements to the creation of a fully functional AI Agent ready for demonstration. Throughout this process, we highlighted the critical importance of selecting the right model for function calling in AI agents. We also explored fallback strategies and refined prompt techniques to enhance the agent’s performance. While function calling accuracy is still an area requiring further development, this experiment establishes a strong foundation for building and improving AI agents capable of handling business tasks.
Additionally, we identified a key issue that needs to be addressed: the need to trace data flow within the agent. We prefer to not rely on the LangChain ecosystem (especially considering that LangSmith is not free), therefore we plan to tackle agent Observability in the upcoming post(s) using widely adopted software design patterns. Another important thing to address would be, how would things change in a multi-agent setup, i.e. where there is a need for orchestration and aggregation of values returned by agents (into one unified and cohesive response sent back to the users).
Stay tuned for more insights as we continue to publicly refine and advance our approach!